빅데이터분석기사 작업형3 가설검정 풀이법은 처음 보면 막막하지만, 실은 외워야 할 코드가 10줄 남짓입니다. 작업형1·2는 코드 길이로 승부가 갈리는 반면, 작업형3는 scipy.stats 함수 한 줄이면 통계량과 p-value가 동시에 떨어집니다.
문제는 그 한 줄을 정확히 어떤 함수로, 어떤 인자 순서로, 어떤 자릿수로 답하느냐죠. 6회 시험 이후 누적된 출제 패턴을 정리해, t검정·카이제곱·분산분석·회귀까지 시험장에서 바로 쓰는 풀이 템플릿으로 묶었습니다.
목차

작업형3 출제 구조와 답안 작성 규칙
작업형3는 6회 시험부터 도입된 가설검정 영역입니다. 2문제 × 15점 = 총 30점이며, 한 문제당 보통 3~4개의 소문항이 묶여 있습니다.
한 문제를 통째로 날리면 합격선(60점)이 흔들립니다. 작업형1(30점)·작업형2(40점)에서 만점을 받기 어려운 이상, 작업형3에서 최소 20점 이상은 확보해야 안전권입니다.
출제 빈도 높은 7가지 유형
지금까지 출제 패턴을 보면 아래 7가지 안에서 거의 모두 회전합니다.
| 분류 | 세부 유형 | 핵심 함수 |
|---|---|---|
| t검정 | 단일·대응·독립표본 t검정 | scipy.stats.ttest_* |
| 분산분석 | 일원배치 ANOVA | scipy.stats.f_oneway |
| 카이제곱 | 적합도·독립성 검정 | chisquare / chi2_contingency |
| 비모수 | 윌콕슨·만휘트니 | wilcoxon / mannwhitneyu |
| 정규성 | 샤피로윌크 | scipy.stats.shapiro |
| 상관·회귀 | 선형회귀 OLS | statsmodels.api.OLS |
| 분류회귀 | 로지스틱 회귀 | statsmodels Logit |
출제진은 매 회차마다 위 7개 박스에서 2개를 뽑는 구조를 유지하고 있습니다. 모두 외울 필요 없이, 함수 호출 패턴 7개만 손에 익히면 됩니다.
답안 작성 4대 원칙
코드를 맞게 짜고도 답을 틀리는 사례가 의외로 많습니다. 거의 다음 4가지 중 하나입니다.
채점 감점 단골 포인트
① 반올림 자릿수 — 문제에 “소수점 셋째 자리”라고 명시되면 반드시 round(x, 3).
② 통계량 부호 — t검정에서 음수 부호 빠뜨리면 오답.
③ 결론 표현 — “기각/채택”이 아닌 “귀무가설을 기각한다”처럼 문장으로 요구하기도 함.
④ p-value 해석 방향 — 단측 vs 양측 혼동.
특히 답란이 객관식 입력칸이라는 점도 핵심입니다. 코드는 검산용이고, 최종 채점은 답란에 입력한 숫자로만 이뤄집니다.
코드를 정성껏 짜도 답란에 잘못된 자릿수를 입력하면 0점입니다.
시험 환경 패키지 체크
2026년 시험 환경은 Python 3.9 + 사전 안내 패키지(pandas, numpy, scipy, statsmodels, scikit-learn) 기반입니다.
scipy.stats와 statsmodels는 별도 import 필수입니다. 시험장에서 import 한 줄을 빠뜨리면 NameError가 떨어지는 사례가 흔하니, 시작 전 아래 임포트 블록을 통째로 외워두세요.
t검정 3유형 풀이 — 단일·대응·독립표본
t검정은 작업형3에서 출제 비중 1위입니다. 6회 이후 매 회차마다 한 문제는 t검정 계열이 출제됐습니다.
핵심은 세 가지 유형을 정확히 구분하는 것. 문제 지문의 키워드만 잘 잡으면 함수는 자동 결정됩니다.
유형 구분 키워드
| 유형 | 지문 키워드 | scipy 함수 |
|---|---|---|
| 단일표본 | “평균이 ○○인지”, “기준값과 비교” | ttest_1samp(x, popmean) |
| 대응표본 | “전후”, “같은 사람의 변화” | ttest_rel(before, after) |
| 독립표본 | “두 집단 비교”, “A그룹 vs B그룹” | ttest_ind(a, b, equal_var=?) |
독립표본의 경우 등분산성 가정 여부에 따라 equal_var 인자가 갈립니다. 문제에서 “등분산을 가정한다”고 명시되면 True, “가정하지 않는다”면 False(Welch’s t-test)로 두면 됩니다.
단일표본 t검정 코드 템플릿
예시: 어떤 음료의 평균 용량이 표기치 250ml와 다른지 검정.
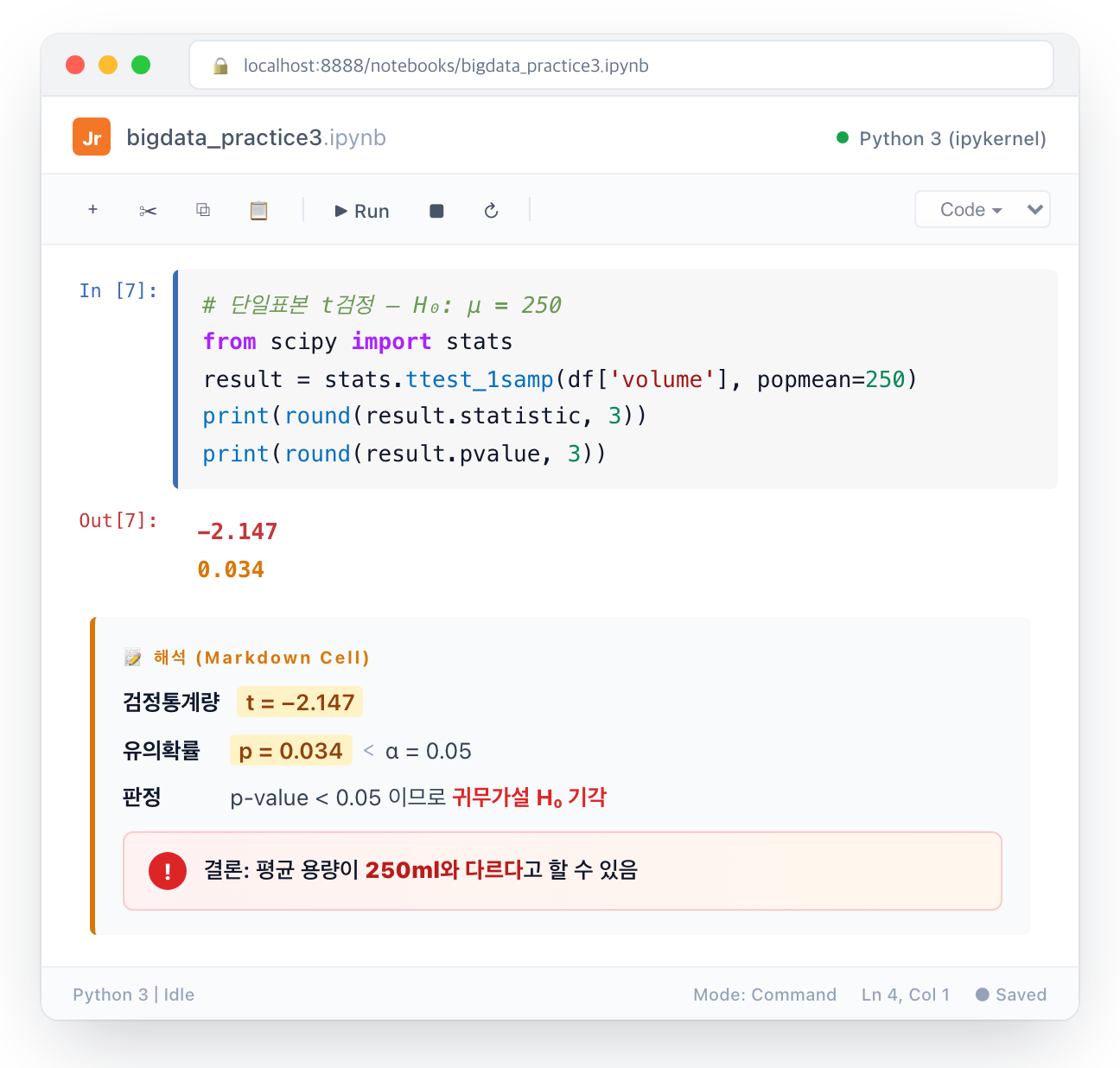
여기서 자주 틀리는 포인트가 있습니다. 답란에 “검정통계량”을 요구하면 statistic(부호 포함)을 넣어야 하고, “|t|값”이라고 명시되면 abs()를 씌워야 합니다.
대응표본·독립표본 코드 템플릿
대응표본은 데이터가 “같은 행 = 같은 대상”으로 정렬돼 있어야 합니다. 결측치가 한쪽이라도 있으면 dropna()로 정리하세요.
독립표본은 보통 long-format 데이터프레임으로 주어집니다. 그룹 컬럼으로 split해서 두 시리즈를 만든 뒤 함수에 넣습니다.
# 대응표본: 다이어트 전후 체중
stats.ttest_rel(df('before'), df('after'))
# 독립표본: 남녀 시험 점수 (등분산 가정)
a = df(df('gender')=='M')('score')
b = df(df('gender')=='F')('score')
stats.ttest_ind(a, b, equal_var=True)실전 팁 — 정규성·등분산성 사전 검정
문제에서 “정규성을 만족하는지 먼저 검정하라”는 소문항이 종종 붙습니다.
• 정규성: stats.shapiro(x) → p > 0.05면 정규성 만족
• 등분산성: stats.levene(a, b) → p > 0.05면 등분산 가정 가능
이 결과에 따라 본 검정의 함수/옵션이 결정되는 흐름이 단골입니다.
비모수 대체 검정
정규성이 깨지면 비모수 검정으로 우회합니다. 함수 이름만 바꾸면 됩니다.
대응표본 t → wilcoxon(before, after), 독립표본 t → mannwhitneyu(a, b). 인자 구조는 동일합니다.
정규성 검정 → 본 검정 → 결론, 이 3단계가 한 문제 안에 묶이는 게 정석 패턴입니다.
이 섹션 핵심
t검정 3유형은 지문 키워드(전후/두 집단/기준값)로 함수가 결정되고, 등분산·정규성 사전 검정 결과에 따라 옵션 또는 비모수 함수로 갈아탑니다. 부호·자릿수만 정확히 챙기면 만점 영역.
카이제곱·분산분석 풀이 — 적합도·독립성·ANOVA
t검정 다음으로 출제 빈도가 높은 영역이 카이제곱과 분산분석입니다. 두 영역 모두 scipy.stats 함수 한 줄로 끝나지만, 입력 데이터 구조를 잘못 잡으면 통째로 틀립니다.
카이제곱 적합도 검정
적합도 검정은 “관측 빈도가 기대 비율과 일치하는가”를 보는 검정입니다. 입력은 관측값 리스트와 기대값 리스트 두 개.
예시: 주사위 60번 던진 결과가 균등분포(각 10회)에 적합한지 검정.
obs = (8, 12, 9, 11, 13, 7)
exp = (10, 10, 10, 10, 10, 10)
chi2, p = stats.chisquare(f_obs=obs, f_exp=exp)
print(round(chi2, 3), round(p, 3))주의: 기대값의 합과 관측값의 합이 다르면 ValueError가 뜹니다. 기대 비율만 주어졌다면 총합 × 기대비율로 환산해서 넣어야 합니다.
카이제곱 독립성 검정
독립성 검정은 두 범주형 변수가 서로 독립인지 보는 검정입니다. 입력은 교차표(contingency table) 하나.
판다스의 crosstab으로 교차표를 만들고 그대로 chi2_contingency에 넣으면 4개 값(통계량, p-value, 자유도, 기대도수)이 한 번에 떨어집니다.
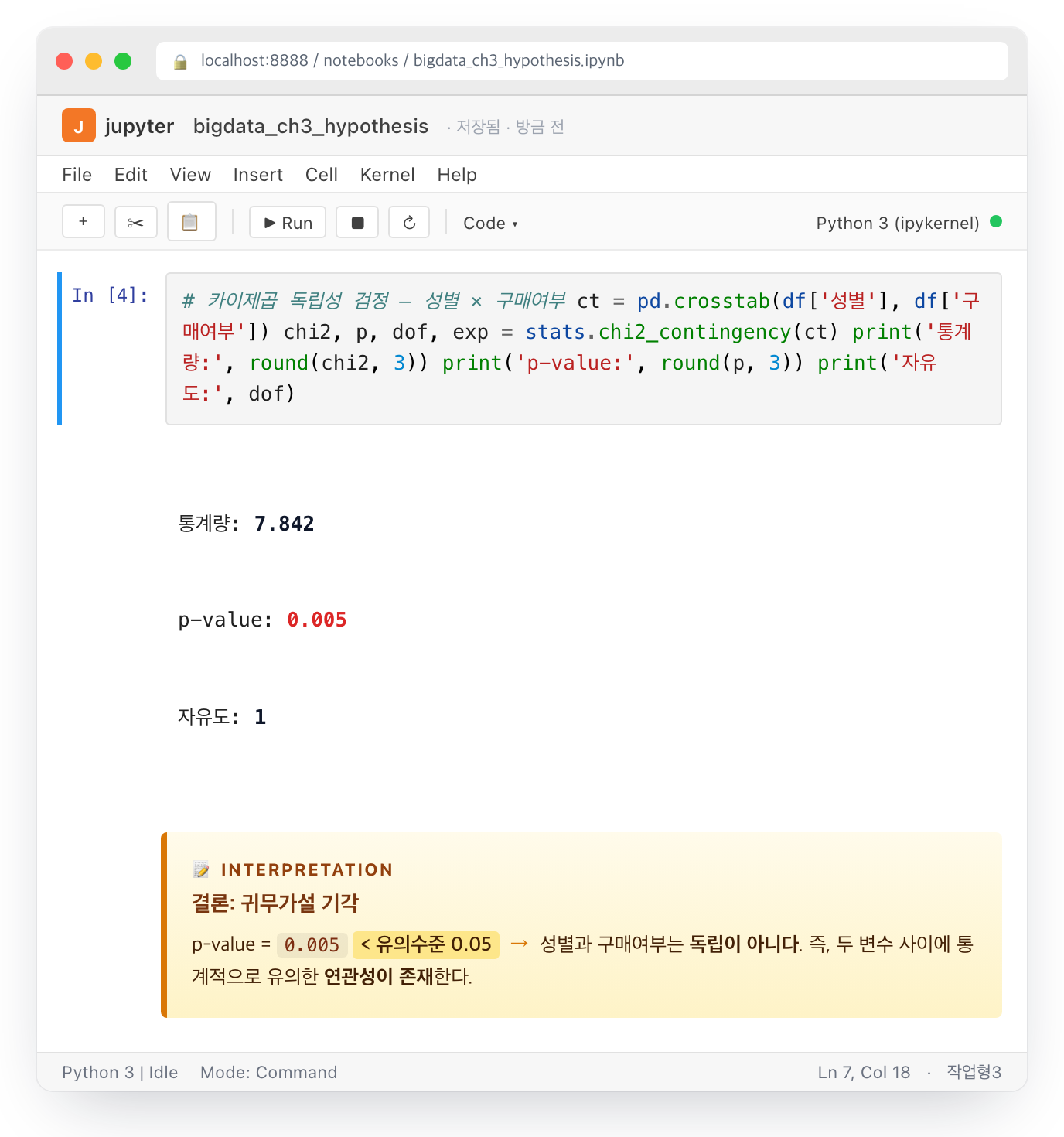
독립성 검정에서 흔한 실수는 기대도수가 5 미만인 셀이 20%를 넘는지 확인하지 않는 것. 만약 그렇다면 피셔의 정확검정(stats.fisher_exact)으로 갈아타야 합니다.
일원배치 분산분석(ANOVA)
세 그룹 이상의 평균이 같은지를 보는 검정입니다. 두 그룹이면 t검정, 세 그룹부터는 ANOVA로 분기됩니다.
g1 = df(df('method')=='A')('score')
g2 = df(df('method')=='B')('score')
g3 = df(df('method')=='C')('score')
f, p = stats.f_oneway(g1, g2, g3)
print(round(f, 3), round(p, 4))statsmodels로 풀면 ANOVA 표 전체가 출력되어 제곱합·평균제곱·F통계량을 한꺼번에 답란에 채울 수 있습니다.
from statsmodels.formula.api import ols
import statsmodels.api as sm
model = ols('score ~ C(method)', data=df).fit()
print(sm.stats.anova_lm(model, typ=2))실전 팁 — 사후검정까지 묻는 경우
“어느 그룹 간 차이가 유의한가”를 묻는 소문항이 따라붙기도 합니다. 이때는 statsmodels.stats.multicomp.pairwise_tukeyhsd로 Tukey HSD를 돌려, p-adj 값을 비교하면 됩니다. 출제된 적은 적지만, 7회 이후 점진적으로 등장 비중이 늘고 있습니다.
카이제곱은 빈도, ANOVA는 평균. 이 한 줄만 외워도 함수 선택 실수가 사라집니다.
회귀·로지스틱회귀 풀이와 시험 직전 체크리스트
회귀분석은 statsmodels의 OLS를 쓰는 게 표준입니다. scikit-learn은 계수만 주고 p-value를 안 주기 때문에, 작업형3에서는 statsmodels가 사실상 유일한 정답입니다.
선형회귀 풀이 템플릿
예시: 광고비(x)가 매출(y)에 미치는 영향을 분석. 회귀계수, p-value, 결정계수, 특정 x값의 예측치를 차례로 묻는 패턴이 흔합니다.
import statsmodels.api as sm
X = sm.add_constant(df('ad_cost'))
y = df('sales')
model = sm.OLS(y, X).fit()
print(model.summary())
# 답란 입력값 추출
print(round(model.params('ad_cost'), 3)) # 회귀계수
print(round(model.pvalues('ad_cost'), 4)) # p-value
print(round(model.rsquared, 3)) # 결정계수
print(round(model.predict((1, 100))(0), 2))# 광고비 100일 때 예측add_constant를 빼먹으면 절편이 사라져 모든 결과가 어긋납니다. 가장 흔한 실수 1순위.
다중회귀는 X에 여러 컬럼을 통째로 넣으면 됩니다. sm.add_constant(df(('x1','x2','x3'))) 형태.
로지스틱 회귀 풀이 템플릿
이항 종속변수(0/1)일 때 사용합니다. 함수만 Logit으로 바뀌고 나머지 호출 패턴은 OLS와 동일합니다.
X = sm.add_constant(df(('age','income')))
y = df('purchase') # 0 또는 1
model = sm.Logit(y, X).fit(disp=0)
print(round(model.params('age'), 4)) # 회귀계수
print(round(np.exp(model.params('age')), 4)) # 오즈비
print(round(model.pvalues('income'), 4)) # p-value오즈비(odds ratio)를 묻는 소문항이 단골입니다. 회귀계수에 exp를 씌운 값이 오즈비라는 점만 기억하면 됩니다.
시험 직전 1주 체크리스트
마지막 일주일은 새 개념보다 코드 손가락 기억에 시간을 쓰는 게 효율적입니다. 다음 항목을 종이에 쓰지 않고 빈 셀에 즉답할 수 있어야 합니다.
- scipy/statsmodels 임포트 5줄을 5초 안에 타이핑
- t검정 3유형 함수명과 인자 순서
- 정규성(shapiro)·등분산성(levene) 검정 결과 해석 방향
- chisquare vs chi2_contingency 입력 데이터 차이
- OLS 호출 시 add_constant 필수
- 오즈비 = exp(회귀계수) 변환
- 반올림 자릿수와 통계량 부호 처리
여기에 더해 작업형2 모델링 답안 사례를 함께 정리해두면, 시험 당일 작업형 전체의 흐름이 머릿속에 체화됩니다. 작업형3는 점수 효율이 가장 높은 영역이라, 30점 중 25점 이상을 목표로 두고 준비하는 것이 합격의 안전판입니다.
전체 핵심 요약
작업형3는 ① 7가지 함수 패턴 암기, ② 지문 키워드로 함수 선택, ③ 자릿수·부호 정확히, ④ add_constant·equal_var 같은 단골 함정 회피. 이 4박자만 맞추면 30점 만점도 충분히 노릴 수 있습니다.
자주 묻는 질문
Q. 작업형3에서 R과 Python 중 어느 쪽이 유리한가요?
출제 의도 자체는 두 언어 모두 동일하게 풀 수 있게 설계됩니다. 다만 일부 회차에서 사전 안내 패키지의 제약으로 Python 응시자가 불이익을 받았던 사례가 있어, 시험위원회가 전원 정답 처리한 적이 있습니다. 그럼에도 데이터 핸들링은 pandas가 압도적으로 편하므로, 이미 Python 기반으로 작업형1·2를 준비했다면 그대로 가는 것이 일관성 측면에서 유리합니다.
Q. summary() 출력을 답란에 그대로 붙여넣으면 안 되나요?
안 됩니다. 답란은 한 줄 입력칸이며, 보통 통계량·p-value·결정계수 같은 단일 수치를 요구합니다. summary()는 검산용으로만 쓰고, 최종 답은 model.params, model.pvalues, model.rsquared 같은 속성으로 정확히 추출해 반올림 후 입력하세요.
Q. 정규성 검정에서 p-value가 0.04처럼 애매하게 나오면 어떻게 하나요?
유의수준이 명시되지 않았다면 0.05 기준으로 판단합니다. p가 0.05 미만이면 정규성을 기각하고 비모수 검정(wilcoxon, mannwhitneyu)으로 갈아타는 것이 안전합니다. 단, 문제에서 “정규성을 가정한다”고 명시했다면 검정 결과와 무관하게 본 검정을 그대로 진행하면 됩니다.
Q. 카이제곱 독립성 검정에서 기대도수가 작을 때 어떻게 처리하나요?
모든 셀의 기대도수가 5 이상이면 chi2_contingency를 그대로 사용합니다. 기대도수 5 미만 셀이 전체의 20%를 넘으면 카이제곱 가정이 깨지므로, 2×2 표라면 stats.fisher_exact로 피셔의 정확검정을 적용해야 합니다. 다만 시험에서는 보통 가정이 만족되도록 데이터가 설계되어 출제됩니다.
Q. 작업형3 30점 중 몇 점이면 합격선이 안전한가요?
합격선은 총 60점입니다. 작업형1(30점)에서 24점, 작업형2(40점)에서 24점 정도가 평균적인 득점이라고 보면, 작업형3에서 최소 12점, 안정권은 20점 이상입니다. 다만 작업형3는 코드량이 적고 채점 자체가 자릿수 매칭 위주라, 준비만 잘 해두면 25~30점 만점도 충분히 가능합니다. 한 문제(15점)는 통째로 맞히겠다는 전략으로 접근하세요.